Quickstart: Patterns and Best Practices
Installation
To install Highcharts Stock for Python, just execute:
$ pip install highcharts-stock
Importing Highcharts Stock for Python Objects
Tip
Best Practice!
This method of importing Highcharts Stock for Python objects yields the fastest
performance for the import statement. However, it is more verbose and requires
you to navigate the extensive Highcharts Stock for Python API.
# Import classes using precise module indications. For example:
from highcharts_stock.chart import Chart
from highcharts_stock.global_options.shared_options import SharedStockOptions
from highcharts_stock.options import HighchartsStockOptions
from highcharts_stock.options.plot_options.bar import BarOptions
from highcharts_stock.options.series.bar import BarSeries
Caution
This method of importing Highcharts Stock for Python classes has relatively slow performance because it imports hundreds of different classes from across the entire library. This performance impact may be acceptable to you in your use-case, but do use at your own risk.
# Import objects from the catch-all ".highcharts" module.
from highcharts_stock import highcharts
# You can now access specific classes without individual import statements.
highcharts.Chart
highcharts.SharedStockOptions
highcharts.HighchartsStockOptions
highcharts.BarOptions
highcharts.BarSeries
Standardizing Your Charts
Tip
Best practice!
We really like to use JS literals written as separate files in our codebase. It
makes it super simple to instantiate a
SharedOptions
instance with one method call.
Let’s say you organize your files like so:
my_repository/| — docs/| — my_project/| —— project_resources/| ——— image_files/| ——— data_files/| ———— data-file-01.csv| ———— data-file-02.csv| ———— data-file-03.csv| ——— highcharts_config/| ———— shared_options.js| ———— bar-template-01.js| ———— bar-template-02.js| ———— line-template.js| ———— packed-bubble-template.js| —— some_package/| ——— __init__.py| ——— package_module.py| ——— another_module.py| —— __init__.py| —— __version__.py| —— some_module.py| — tests/| — .gitignore| — requirements.txt
You’ll notice that the organization has a project_resources folder. This is where
you would put the various files that your application wlil reference, like your static
images, or the files that contain data you might be using in your application. It also
contains a highcharts_config folder, which contains several files with a .js
extension. Of particular note is the file in bold, shared_options.js. This file
should contain a
JavaScript object literal
version of the configuration settings you want to apply to all of your
visualizations. This file might look something like this:
{ chart: { backgroundColor: { linearGradient: { x1: 0, x2: 0, y1: 1, y2: 1 }, stops: [ [0, 'rgb(255, 255, 255)'], [1, 'rgb(240, 240, 255)'] ] }, borderWidth: 2, plotBackgroundColor: 'rgba(255, 255, 255, .9)', plotBorderWidth: 1 }, caption: { align: 'center', floating: true, margin: 20, verticalAlign: 'top' }, credits: { enabled: true, href: 'https://www.somewhere.com', style: { color: '#cccccc', fontSize: '8px' }, text: 'Highcharts for Python' } }
Now with this file, you can easily create a
SharedOptions
instance by executing:
from highcharts_stock.highcharts import SharedOptions my_shared_options = SharedOptions.from_js_literal('../../project_resources/highcharts_config/shared_options.js')
And that’s it! Now you have a
SharedOptions
instance that can be used to apply your configuration standards to all of your charts.
You can do that by delivering its JavaScript output to your front-end by calling:
js_code_snippet = my_shared_options.to_js_literal()
which will produce a string as follows:
Highcharts.setOptions({ caption: { align: 'center', floating: true, margin: 20, verticalAlign: 'top' }, chart: { backgroundColor: { linearGradient: { x1: 0.0, x2: 0.0, y1: 1.0, y2: 1.0 }, stops: [ [0, 'rgb(255, 255, 255)'], [1, 'rgb(240, 240, 255)'] ] }, borderWidth: 2, plotBackgroundColor: 'rgba(255, 255, 255, .9)', plotBorderWidth: 1 }, credits: { enabled: true, href: 'https://www.somewhere.com', style: { color: '#cccccc', fontSize: '8px' }, text: 'Highcharts for Python' } });
And now you can deliver js_code_snippet to your HTML template or wherever it will
be rendered.
You can use the same exact pattern as using a JS literal with a JSON file instead. We don’t really think there’s an advantage to this - but there might be one significant disadvantage: JSON files cannot be used to provide JavaScript functions to your Highcharts configuration. This means that formatters, event handlers, etc. will not be applied through your shared options if you use a JSON file.
If your shared options don’t require JavaScript functions? Then by all means, feel
free to use a JSON file and the .from_json() method instead.
With a file structure like:
my_repository/| — docs/| — my_project/| —— project_resources/| ——— image_files/| ——— data_files/| ———— data-file-01.csv| ———— data-file-02.csv| ———— data-file-03.csv| ——— highcharts_config/| ———— shared_options.json| ———— bar-template.json| ———— line-template.json| ———— packed-bubble-template.json| —— some_package/| ——— __init__.py| ——— package_module.py| ——— another_module.py| —— __init__.py| —— __version__.py| —— some_module.py| — tests/| — .gitignore| — requirements.txt
You can leverage shared options that read from
my_project/project_resources/highcharts_config/shared_options.json by executing:
from highcharts_stock.highcharts import SharedOptions my_shared_options = SharedOptions.from_js_literal( '../../project_resources/highcharts_config/shared_options.json' ) json_code_snippet = my_shared_options.to_js_literal()
If you are hoping to configure a simple set of options, one of the fastest ways to do
so in your Python code is to instantiate your
SharedOptions
instance from a simple dict:
as_dict = { 'chart': { 'backgroundColor': '#fff', 'borderWidth': 2, 'plotBackgroundColor': 'rgba(255, 255, 255, 0.9)', 'plotBorderWidth': 1 } } my_shared_options = SharedOptions.from_dict(as_dict) js_code_snippet = my_shared_options.to_js_literal()Tip
This method is particularly helpful and easy to maintain if you are only using a very small subset of the Highcharts JS configuration options.
Tip
Best practice!
We really like to use JS literals written as separate files in our codebase. It makes it super simple to instantiate a Highcharts Stock for Python instance with one method call.
Let’s say you organize your files like so:
my_repository/| — docs/| — my_project/| —— project_resources/| ——— image_files/| ——— data_files/| ———— data-file-01.csv| ———— data-file-02.csv| ———— data-file-03.csv| ——— highcharts_config/| ———— shared_options.js| ———— hlc-template-01.js| ———— hlc-template-02.js| ———— line-template.js| ———— packed-bubble-template.js| —— some_package/| ——— __init__.py| ——— package_module.py| ——— another_module.py| —— __init__.py| —— __version__.py| —— some_module.py| — tests/| — .gitignore| — requirements.txt
As you can see, there are two JS literal files named hlc-template-01.js and
hlc-template-02.js respectively. These template files can be used to significantly
accelerate the configuration of our bar charts. Each template corresponds to one
sub-type of bar chart that we know we will need. These sub-types may have different
event functions, or more frequently use different formatting functions to make the
data look the way we want it to look.
Now with these template files, we can easily create a pair of
Chart instances by executing:
from highcharts_stock.highcharts import Chart from highcharts_stock.options.series.hlc import HLCSeries type_1_chart = Chart.from_js_literal( '../../project_resources/highcharts_config/hlc-template-01.js' ) type_2_chart = Chart.from_js_literal( '../../project_resources/highcharts_config/hlc-template-02.js' )
And that’s it! Now you have two chart instances which you can further modify. For example, you can add data to them by calling:
type_1_chart.container = 'chart1_div' type_2_chart.container = 'chart2_div' type_1_chart.add_series(HLCSeries.from_csv('../../project_resources/data_files/data-file-01.csv')) type_2_chart.add_series(HLCSeries.from_csv('../../project_resources/data_files/data-file-02.csv'))
And then you can create the relevant JavaScript code to render the chart using:
type_1_chart_js = type_1_chart.to_js_literal() type_2_chart_js = type_2_chart.to_js_literal()
And now you can deliver type_1_chart_js and type_2_chart_js to your HTML
template or wherever it will be rendered.
If you have an existing Highcharts for Python instance, you can copy its
properties to another object using the .copy() method. You can therefore set up
one chart, and then copy its properties to other chart objects with one method call.
type_1_chart = Chart.from_js_literal('../../project_resources/highcharts_config/line-template-01.js') other_chart = type_1_chart.copy(other_chart, overwrite = True)Tip
The
Chart.copy()method supports a special keyword argument,preverse_datawhich if set toTruewill copy properties (unlessoverwrite = False) but will not overwrite any data. This can be very useful to replicating the configuration of your chart across multiple charts that have different series and data.other_chart = Chart() other_chart.add_series( LineSeries.from_csv('../../project_resources/data_files/data-file-02.csv') ) other_chart = type_1_chart.copy(other_chart, preserve_data = True)
If you are hoping to configure a simple set of template settings, one of the fastest
ways to do so in your Python code is to instantiate your
Chart instance from a simple
dict using the .from_dict() method.
Tip
This method is particularly helpful and easy to maintain if you are only using a very small subset of the Highcharts JS configuration options.
Populating Series with Data
my_series = LineSeries()
# EXAMPLE 1
# A simple array of numerical values which correspond to the Y value of the data
# point
my_series.data = [0, 5, 3, 5]
# EXAMPLE 2
# An array containing 2-member arrays (corresponding to the X and Y values of the
# data point)
my_series.data = [
[0, 0],
[1, 5],
[2, 3],
[3, 5]
]
# EXAMPLE 3
# An array of dict with named values
my_series.data = [
{
'x': 0,
'y': 0,
'name': 'Point1',
'color': '#00FF00'
},
{
'x': 1,
'y': 5,
'name': 'Point2',
'color': '#CCC'
},
{
'x': 2,
'y': 3,
'name': 'Point3',
'color': '#999'
},
{
'x': 3,
'y': 5,
'name': 'Point4',
'color': '#000'
}
]
from highcharts_stock.options.series.area import LineSeries
from highcharts_stock.options.series.data.cartesian import CartesianData
from highcharts_stock.options.series.data.cartesian import CartesianDataCollection
# Creating CartesianData instances from an array
# EXAMPLE 1
# A simple array of numerical values which correspond to the Y value of the data
# point
my_data = CartesianData.from_array([0, 5, 3, 5])
# EXAMPLE 2
# An array containing 2-member arrays (corresponding to the X and Y values of the
# data point)
my_data = CartesianData.from_array([
[0, 0],
[1, 5],
[2, 3],
[3, 5]
])
# EXAMPLE 3
# An array of dict with named values
my_data = CartesianData.from_array([
{
'x': 0,
'y': 0,
'name': 'Point1',
'color': '#00FF00'
},
{
'x': 1,
'y': 5,
'name': 'Point2',
'color': '#CCC'
},
{
'x': 2,
'y': 3,
'name': 'Point3',
'color': '#999'
},
{
'x': 3,
'y': 5,
'name': 'Point4',
'color': '#000'
}
])
# EXAMPLE 5
# using a NumPy ndarray named "numpy_array"
my_data = CartesianData.from_array(numpy_array)
my_series = LineSeries(data = my_data)
# Creating a CartesianDataCollection instance from an array
# EXAMPLE 1
# A simple array of numerical values which correspond to the Y value of the data
# point
my_data = CartesianDataCollection.from_array([0, 5, 3, 5])
# EXAMPLE 2
# An array containing 2-member arrays (corresponding to the X and Y values of the
# data point)
my_data = CartesianDataCollection.from_array([
[0, 0],
[1, 5],
[2, 3],
[3, 5]
])
# EXAMPLE 3
# An array of dict with named values
my_data = CartesianDataCollection.from_array([
{
'x': 0,
'y': 0,
'name': 'Point1',
'color': '#00FF00'
},
{
'x': 1,
'y': 5,
'name': 'Point2',
'color': '#CCC'
},
{
'x': 2,
'y': 3,
'name': 'Point3',
'color': '#999'
},
{
'x': 3,
'y': 5,
'name': 'Point4',
'color': '#000'
}
])
# EXAMPLE 5
# using a NumPy ndarray named "numpy_array"
my_data = CartesianDataCollection.from_array(numpy_array)
my_series = LineSeries(data = my_data)
# Creating CartesianData instances from an array
# EXAMPLE 1
# A simple array of numerical values which correspond to the Y value of the data
# point
my_series = LineSeries.from_array([0, 5, 3, 5])
# EXAMPLE 2
# An array containing 2-member arrays (corresponding to the X and Y values of the
# data point)
my_series = LineSeries.from_array([
[0, 0],
[1, 5],
[2, 3],
[3, 5]
])
# EXAMPLE 3
# An array of dict with named values
my_series = LineSeries.from_array([
{
'x': 0,
'y': 0,
'name': 'Point1',
'color': '#00FF00'
},
{
'x': 1,
'y': 5,
'name': 'Point2',
'color': '#CCC'
},
{
'x': 2,
'y': 3,
'name': 'Point3',
'color': '#999'
},
{
'x': 3,
'y': 5,
'name': 'Point4',
'color': '#000'
}
])
# EXAMPLE 5
# using a NumPy ndarray named "numpy_array"
my_series = LineSeries.from_array(numpy_array)
Method Signature
See also
Chart.from_array()
- classmethod from_array(cls, value)
Creates a collection of data point instances, parsing the contents of
valueas an array (iterable). This method is specifically used to parse data that is input to Highcharts for Python without property names, in an array-organized structure as described in the Highcharts JS documentation.See also
The specific structure of the expected array is highly dependent on the type of data point that the series needs, which itself is dependent on the series type itself.
Please review the detailed series documentation for series type-specific details of relevant array structures.
- Parameters:
value (iterable) –
The value that should contain the data which will be converted into data point instances.
Note
If
valueis not an iterable, it will be converted into an iterable to be further de-serialized correctly.- Returns:
Collection of data point instances (descended from
DataBase)- Return type:
:class:`list <python:list> of
DataBase-descendant instances, orDataPointCollection
# EXAMPLE 1
# A simple array of numerical values which correspond to the Y value of the data
# point
my_series.load_from_array([0, 5, 3, 5])
# EXAMPLE 2
# An array containing 2-member arrays (corresponding to the X and Y values of the
# data point)
my_series.load_from_array([
[0, 0],
[1, 5],
[2, 3],
[3, 5]
])
# EXAMPLE 3
# An array of dict with named values
my_series.load_from_array([
{
'x': 0,
'y': 0,
'name': 'Point1',
'color': '#00FF00'
},
{
'x': 1,
'y': 5,
'name': 'Point2',
'color': '#CCC'
},
{
'x': 2,
'y': 3,
'name': 'Point3',
'color': '#999'
},
{
'x': 3,
'y': 5,
'name': 'Point4',
'color': '#000'
}
])
# EXAMPLE 5
# using a NumPy ndarray named "numpy_array"
my_series.load_from_array(numpy_array)
Method Signature
- classmethod load_from_array(cls, value)
Update the series instance’s
dataproperty with data populated from an array-likevalue.This method is specifically used to parse data that is input to Highcharts for Python without property names, in an array-organized structure as described in the Highcharts JS documentation.
See also
The specific structure of the expected array is highly dependent on the type of data point that the series needs, which itself is dependent on the series type itself.
Please review the detailed series documentation for series type-specific details of relevant array structures.
- Parameters:
value (iterable) –
The value that should contain the data which will be converted into data point instances.
Note
If
valueis not an iterable, it will be converted into an iterable to be further de-serialized correctly.
from highcharts_stock.chart import Chart
from highcharts_stock.options.series.area import LineSeries
# Create one or more LineSeries instances from the CSV file "some-csv-file.csv".
# EXAMPLE 1. The minimum code to produce one series for each
# column in the CSV file (excluding the first column):
my_series = LineSeries.from_csv('some-csv-file.csv')
# EXAMPLE 2. Produces ONE series with more precise configuration:
my_series = LineSeries.from_csv('some-csv-file.csv',
property_column_map = {
'x': 0,
'y': 3,
'id': 'id'
})
# EXAMPLE 3. Produces THREE series instances with
# more precise configuration:
my_series = LineSeries.from_csv('some-csv-file.csv',
property_column_map = {
'x': 0,
'y': [3, 5, 8],
'id': 'id'
})
# Create a chart with one or more LineSeries instances from
# the CSV file "some-csv-file.csv".
# EXAMPLE 1: The minimum code:
my_chart = Chart.from_csv('some-csv-file.csv', series_type = 'line')
# EXAMPLE 2: For more precise configuration and *one* series:
my_chart = Chart.from_csv('some-csv-file.csv',
property_column_map = {
'x': 0,
'y': 3,
'id': 'id'
},
series_type = 'line')
# EXAMPLE 3: For more precise configuration and *multiple* series:
my_chart = Chart.from_csv('some-csv-file.csv',
property_column_map = {
'x': 0,
'y': [3, 5, 8],
'id': 'id'
},
series_type = 'line')
Method Signature
- classmethod .from_csv(cls, as_string_or_file, property_column_map=None, series_kwargs=None, has_header_row=True, delimiter=',', null_text='None', wrapper_character="'", line_terminator='\r\n', wrap_all_strings=False, double_wrapper_character_when_nested=False, escape_character='\\', series_in_rows=False, series_index=None, **kwargs)
Create one or more series instances with
.datapopulated from data in a CSV string or file.Note
To produce one or more
LineSeriesinstances, the minimum code required would be:# EXAMPLE 1. The minimum code: my_series = LineSeries.from_csv('some-csv-file.csv') # EXAMPLE 2. For more precise configuration and ONE series: my_series = LineSeries.from_csv('some-csv-file.csv', property_column_map = { 'x': 0, 'y': 3, 'id': 'id' }) # EXAMPLE 3. For more precise configuration and MULTIPLE series: my_series = LineSeries.from_csv('some-csv-file.csv', property_column_map = { 'x': 0, 'y': [3, 5, 8], 'id': 'id' })
As the example above shows, data is loaded into the
my_seriesinstance from the CSV file with a filenamesome-csv-file.csv.In EXAMPLE 1, the method will return one or more series where each series will default to having its
.xvalues taken from the first (index 0) column in the CSV, and oneLineSeriesinstance will be created for each subsequent column (which will populate that series’.yvalues.In EXAMPLE 2, the chart will contain one series, where the
.xvalues for each data point will be taken from the first (index 0) column in the CSV file. The.yvalues will be taken from the fourth (index 3) column in the CSV file. And the.idvalues will be taken from a column whose header row is labeled'id'(regardless of its index).In EXAMPLE 3, the chart will contain three series, all of which will have
.xvalues taken from the first (index 0) column,.idvalues from the column whose header row is labeled'id', and whose.ywill be taken from the fourth (index 3) column for the first series, the sixth (index 5) column for the second series, and the ninth (index 8) column for the third series.- Parameters:
as_string_or_file (
stror Path-like) –The CSV data to use to pouplate data. Accepts either the raw CSV data as a
stror a path to a file in the runtime environment that contains the CSV data.Tip
Unwrapped empty column values are automatically interpreted as null (
None).property_column_map (
dict) –A
dictused to indicate which data point property should be set to which CSV column. The keys in thedictshould correspond to properties in the data point class, while the value can either be a numerical index (starting with 0) or astrindicating the label for the CSV column.Note
If any of the values in
property_column_mapcontain an iterable, then one series will be produced for each item in the iterable. For example, the following:{ 'x': 0, 'y': [3, 5, 8] }
will return three series, each of which will have its
.xvalue populated from the first column (index 0), and whose.yvalues will be populated from the fourth, sixth, and ninth columns (indices 3, 5, and 8), respectively.series_type (
str) –Indicates the series type that should be created from the CSV data. Defaults to
'line'.Warning
This argument is not supported when calling
.from_csv()on a series instance. It is only supported when callingChart.from_csv().has_header_row (
bool) – IfTrue, indicates that the first row ofas_string_or_filecontains column labels, rather than actual data. Defaults toTrue.series_kwargs (
dict) –An optional
dictcontaining keyword arguments that should be used when instantiating the series instance. Defaults toNone.Warning
If
series_kwargscontains adatakey, its value will be overwritten. Thedatavalue will be created from the CSV file instead.delimiter (
str) – The delimiter used between columns. Defaults to,.wrapper_character (
str) – The string used to wrap string values when wrapping is applied. Defaults to'.null_text (
str) – The string used to indicate an empty value if empty values are wrapped. Defaults to None.line_terminator (
str) – The string used to indicate the end of a line/record in the CSV data. Defaults to'\r\n'.line_terminator –
The string used to indicate the end of a line/record in the CSV data. Defaults to
'\r\n'.Note
The Python
csvcurrently ignores theline_terminatorparameter and always applies'\r\n', by design. The Python docs say this may change in the future, so for future backwards compatibility we are including it here.wrap_all_strings (
bool) –If
True, indicates that the CSV file has all string data values wrapped in quotation marks. Defaults toFalse.double_wrapper_character_when_nested (
bool) – IfTrue, quote character is doubled when appearing within a string value. IfFalse, theescape_characteris used to prefix quotation marks. Defaults toFalse.escape_character (
str) – A one-character string that indicates the character used to escape quotation marks if they appear within a string value that is already wrapped in quotation marks. Defaults to\\(which is Python for'\', which is Python’s native escape character).series_in_rows (
bool) – ifTrue, will attempt a streamlined cartesian series with x-values taken from column names, y-values taken from row values, and the series name taken from the row index. Defaults toFalse.series_index (
int, slice, orNone) – ifNone, will attempt to populate the chart with multiple series from the CSV data. If anintis supplied, will populate the chart only with the series found atseries_index.**kwargs –
Remaining keyword arguments will be attempted on the resulting series instance and the data points it contains.
- Returns:
One or more series instances (descended from
SeriesBase) with its.dataproperty populated from the CSV data inas_string_or_file.- Return type:
listof series instances (descended fromSeriesBase) orSeriesBaseinstance- Raises:
HighchartsCSVDeserializationError – if
property_column_mapreferences CSV columns by their label, but the CSV data does not contain a header row
# Given a LineSeries named "my_series", and a CSV file named "updated-data.csv"
my_series.load_from_csv('updated-data.csv')
# For more precise control over how the CSV data is parsed,
# you can supply a mapping of series properties to their CSV column
# either by index position *or* by column header name.
my_series.load_from_csv('updated-data.csv',
property_column_map = {
'x': 0,
'y': 3,
'id': 'id'
})
Method Signature
- .load_from_csv(self, as_string_or_file, property_column_map=None, has_header_row=True, delimiter=',', null_text='None', wrapper_character="'", line_terminator='\r\n', wrap_all_strings=False, double_wrapper_character_when_nested=False, escape_character='\\', series_in_rows='line', series_index=None, **kwargs)
Updates the series instance with a collection of data points (descending from
DataBase) fromas_string_or_fileby traversing the rows of data and extracting the values from the columns indicated inproperty_column_map.Warning
This method will overwrite the contents of the series instance’s
dataproperty.Note
For an example
LineSeries, the minimum code required would be:my_series = LineSeries() # Minimal code - will attempt to update the line series # taking x-values from the first column, and y-values from # the second column. If there are too many columns in the CSV, # will throw an error. my_series = my_series.from_csv('some-csv-file.csv') # More precise code - will attempt to update the line series # mapping columns in the CSV file to properties on the series # instance. my_series = my_series.from_csv('some-csv-file.csv', property_column_map = { 'x': 0, 'y': 3, 'id': 'id' })
As the example above shows, data is loaded into the
my_seriesinstance from the CSV file with a filenamesome-csv-file.csv. Unless otherwise specified, the.xvalues for each data point will be taken from the first (index 0) column in the CSV file, while the.yvalues will be taken from the second column.If the CSV has more than 2 columns, then this will throw an
HighchartsCSVDeserializationErrorbecause the function is not certain which columns to use to update the series. If this happens, you can precisely specify which columns to use by providing aproperty_column_mapargument, as shown in the second example. In that second example, the.xvalues for each data point will be taken from the first (index 0) column in the CSV file. The.yvalues will be taken from the fourth (index 3) column in the CSV file. And the.idvalues will be taken from a column whose header row is labeled'id'(regardless of its index).- Parameters:
as_string_or_file (
stror Path-like) –The CSV data to load, either as a
stror as the name of a file in the runtime envirnoment. If a file, data will be read from the file.Tip
Unwrapped empty column values are automatically interpreted as null (
None).property_column_map (
dict) –An optional
dictused to indicate which data point property should be set to which CSV column. The keys in thedictshould correspond to properties in the data point class, while the value can either be a numerical index (starting with 0) or astrindicating the label for the CSV column. Defaults toNone.has_header_row (
bool) – IfTrue, indicates that the first row ofas_string_or_filecontains column labels, rather than actual data. Defaults toTrue.delimiter (
str) – The delimiter used between columns. Defaults to,.wrapper_character (
str) – The string used to wrap string values when wrapping is applied. Defaults to'.null_text (
str) – The string used to indicate an empty value if empty values are wrapped. Defaults to None.line_terminator (
str) –The string used to indicate the end of a line/record in the CSV data. Defaults to
'\r\n'.Warning
The Python
csvmodule currently ignores theline_terminatorparameter and always applies'\r\n', by design. The Python docs say this may change in the future, so for future backwards compatibility we are including it here.wrap_all_strings (
bool) –If
True, indicates that the CSV file has all string data values wrapped in quotation marks. Defaults toFalse.double_wrapper_character_when_nested (
bool) – IfTrue, quote character is doubled when appearing within a string value. IfFalse, theescape_characteris used to prefix quotation marks. Defaults toFalse.escape_character (
str) – A one-character string that indicates the character used to escape quotation marks if they appear within a string value that is already wrapped in quotation marks. Defaults to\\(which is Python for'\', which is Python’s native escape character).series_in_rows (
bool) – ifTrue, will attempt a streamlined cartesian series with x-values taken from column names, y-values taken from row values, and the series name taken from the row index. Defaults toFalse.if
None, will raise aHighchartsCSVDeserializationErrorif the CSV data contains more than one series and noproperty_column_mapis provided. Otherwise, will update the instance with the series found in the CSV at theseries_indexvalue. Defaults toNone.Tip
This argument is ignored if
property_column_mapis provided.**kwargs –
Remaining keyword arguments will be attempted on the resulting series instance and the data points it contains.
- Returns:
A collection of data points descended from
DataBaseas appropriate for the series class.- Return type:
listof instances descended fromDataBase- Raises:
HighchartsDeserializationError – if unable to parse the CSV data correctly
# Given a Pandas DataFrame instance named "df"
from highcharts_stock.chart import Chart
from highcharts_stock.options.series.area import LineSeries
# Creating a Series from the DataFrame
## EXAMPLE 1. Minimum code required. Creates one or more series.
my_series = LineSeries.from_pandas(df)
## EXAMPLE 2. More precise configuration. Creates ONE series.
my_series = LineSeries.from_pandas(df, series_index = 2)
## EXAMPLE 3. More precise configuration. Creates ONE series.
my_series = LineSeries.from_pandas(df,
property_map = {
'x': 'date',
'y': 'value',
'id': 'id'
})
## EXAMPLE 4. More precise configuration. Creates THREE series.
my_series = LineSeries.from_pandas(df,
property_map = {
'x': 'date',
'y': ['value1', 'value2', 'value3'],
'id': 'id'
})
## EXAMPLE 5. Minimum code required. Creates one or more series
## from a dataframe where each row in the dataframe is a
## Highcharts series. The two lines of code below are equivalent.
my_series = LineSeries.from_pandas_in_rows(df)
# Creating a Chart with a lineSeries from the DataFrame.
## EXAMPLE 1. Minimum code required. Populates the chart with
## one or more series.
my_chart = Chart.from_pandas(df)
## EXAMPLE 2. More precise configuration. Populates the chart with
## one series.
my_chart = Chart.from_pandas(df, series_index = 2)
## EXAMPLE 3. More precise configuration. Populates the chart with
## ONE series.
my_chart = Chart.from_pandas(df,
property_map = {
'x': 'date',
'y': 'value',
'id': 'id'
},
series_type = 'line')
## EXAMPLE 4. More precise configuration. Populates the chart with
## THREE series.
my_chart = Chart.from_pandas(df,
property_map = {
'x': 'date',
'y': ['value1', 'value2', 'value3'],
'id': 'id'
},
series_type = 'line')
## EXAMPLE 5. Minimum code required. Creates a Chart populated
## with series from a dataframe where each row in the dataframe
## becomes a series on the chart.
my_chart = Chart.from_pandas_in_rows(df)
Method Signature
- classmethod .from_pandas(cls, df, property_map=None, series_kwargs=None, series_in_rows=False, series_index=None, **kwargs)
Create one or more series instances whose
.dataproperties are populated from a pandasDataFrame.- Parameters:
df (
DataFrame) – TheDataFramefrom which data should be loaded.property_map (
dict) –An optional
dictused to indicate which data point property should be set to which column indf. The keys in thedictshould correspond to properties in the data point class, while the value should indicate the label for theDataFramecolumn.Note
If any of the values in
property_mapcontain an iterable, then one series will be produced for each item in the iterable. For example, the following:{ 'x': 'timestamp', 'y': ['value1', 'value2', 'value3'] }
will return three series, each of which will have its
.xvalue populated from the column labeled'timestamp', and whose.yvalues will be populated from the columns labeled'value1','value2', and'value3', respectively.series_type (
str) –Indicates the series type that should be created from the CSV data. Defaults to
'line'.Warning
This argument is not supported when calling
.from_pandas()on a series. It is only supported when callingChart.from_csv().series_kwargs (
dict) –An optional
dictcontaining keyword arguments that should be used when instantiating the series instance. Defaults toNone.Warning
If
series_kwargscontains adatakey, its value will be overwritten. Thedatavalue will be created fromdfinstead.series_in_rows (
bool) – ifTrue, will attempt a streamlined cartesian series with x-values taken from column names, y-values taken from row values, and the series name taken from the row index. Defaults toFalse.False.series_index (
int, slice, orNone) – If supplied, return the series that Highcharts for Python generated fromdfat theseries_indexvalue. Defaults toNone, which returns all series generated fromdf.**kwargs –
Remaining keyword arguments will be attempted on the resulting series instance and the data points it contains.
- Returns:
One or more series instances (descended from
SeriesBase) with the.dataproperty populated from the data indf.- Return type:
listof series instances (descended fromSeriesBase), or aSeriesBase-descended instance- Raises:
HighchartsPandasDeserializationError – if
property_mapreferences a column that does not exist in the data frameHighchartsDependencyError – if pandas is not available in the runtime environment
# Given a LineSeries named "my_series", and a Pandas DataFrame variable named "df"
# EXAMPLE 1. The minimum code required to update the series:
my_series.load_from_pandas(df)
# EXAMPLE 2. For more precise control over how the ``df`` is parsed,
# you can supply a mapping of series properties to their dataframe column.
my_series.load_from_pandas(df,
property_map = {
'x': 'date',
'y': 'value',
'id': 'id'
})
# EXAMPLE 3. For more precise control, specify the index of the
# Highcharts for Python series instance to use in updating your series' data.
my_series.load_from_pandas(df, series_index = 3)
Method Signature
- .load_from_pandas(self, df, property_map=None, series_in_rows=False, series_index=None)
Replace the contents of the
.dataproperty with data points populated from a pandasDataFrame.- Parameters:
df (
DataFrame) – TheDataFramefrom which data should be loaded.property_map (
dict) – Adictused to indicate which data point property should be set to which column indf. The keys in thedictshould correspond to properties in the data point class, while the value should indicate the label for theDataFramecolumn.series_in_rows (
bool) – ifTrue, will attempt a streamlined cartesian series with x-values taken from column names, y-values taken from row values, and the series name taken from the row index. Defaults toFalse.series_index (
int, slice, orNone) –If supplied, return the series that Highcharts for Python generated from
dfat theseries_indexvalue. Defaults toNone, which returns all series generated fromdf.Warning
If
Noneand Highcharts for Python generates multiple series, then aHighchartsPandasDeserializationErrorwill be raised.
- Raises:
HighchartsPandasDeserializationError – if
property_mapreferences a column that does not exist in the data frameHighchartsPandasDeserializationError – if
series_indexisNone, and it is ambiguous which series generated from the dataframe should be usedHighchartsDependencyError – if pandas is not available in the runtime environment
# Given a PySpark DataFrame instance named "df"
from highcharts_stock.chart import Chart
from highcharts_stock.options.series.area import LineSeries
# Create a LineSeries from the PySpark DataFrame "df"
my_series = LineSeries.from_pyspark(df,
property_map = {
'x': 'date',
'y': 'value',
'id': 'id'
})
# Create a new Chart witha LineSeries from the DataFrame "df"
my_chart = Chart.from_pyspark(df,
property_map = {
'x': 'date',
'y': 'value',
'id': 'id'
},
series_type = 'line')
Method Signature
See also
- classmethod .from_pyspark(cls, df, property_map, series_kwargs=None)
Create a series instance whose
.dataproperty is populated from a PySparkDataFrame.- Parameters:
df (
DataFrame) – TheDataFramefrom which data should be loaded.property_map (
dict) – Adictused to indicate which data point property should be set to which column indf. The keys in thedictshould correspond to properties in the data point class, while the value should indicate the label for theDataFramecolumn.series_kwargs (
dict) –An optional
dictcontaining keyword arguments that should be used when instantiating the series instance. Defaults toNone.Warning
If
series_kwargscontains adatakey, its value will be overwritten. Thedatavalue will be created fromdfinstead.
- Returns:
A series instance (descended from
SeriesBase) with its.dataproperty populated from the data indf.- Return type:
listof series instances (descended fromSeriesBase)- Raises:
HighchartsPySparkDeserializationError – if
property_mapreferences a column that does not exist in the data frameif PySpark is not available in the runtime environment
# Given a LineSeries named "my_series", and a PySpark DataFrame variable named "df"
my_series.load_from_pyspark(df,
property_map = {
'x': 'date',
'y': 'value',
'id': 'id'
})
Method Signature
- .load_from_pyspark(self, df, property_map)
Replaces the contents of the
.dataproperty with values from a PySparkDataFrame.- Parameters:
df (
DataFrame) – TheDataFramefrom which data should be loaded.property_map (
dict) – Adictused to indicate which data point property should be set to which column indf. The keys in thedictshould correspond to properties in the data point class, while the value should indicate the label for theDataFramecolumn.
- Raises:
HighchartsPySparkDeserializationError – if
property_mapreferences a column that does not exist in the data frameif PySpark is not available in the runtime environment
Adding Technical Indicators
Note
All standard series (descending from
SeriesBase) have an
.add_indicator() method
which can be used to easily configure a new indicator tied to the series in
question.
# Given a series instance in the variable "my_series"
# Create a Chart instance
my_chart = Chart.from_series(my_series)
# Adds a new Simple Moving Average indicator to the chart, based off of the
# "my_series" series.
my_chart = my_series.add_indicator(my_chart, indicator_name = 'sma')
Method Signature
- .add_indicator(chart, indicator_name, indicator_kwargs=None)
- Parameters:
chart (
Chart) – The chart object in which the series is rendered and to which the indicator should be appended.indicator_name (
str) – The name of the indicator that should be added to the series and chart. For the list of supported indicators, please review the Indicator List.indicator_kwargs (
dictorNone) – Keyword arguments to apply when instantiating the new indicator series. Defaults toNone.
- Returns:
chartwith a new indicator series included in its list of configured series.- Return type:
# Given a series instance with ID "my-series-id" in the variable "my_series"
# Create a Chart instance from the series "my_series"
my_chart = Chart.from_series(my_series)
# Add a Simple Moving Average indicator to the series with the ID "my-series-id"
my_chart.add_indicator(indicator_name = 'sma',
series = 'my-series-id')
# Create a new Chart instance
my_chart2 = Chart(options = {})
# Add a Simple Moving Average indicator AND the series with the ID "my-series-id"
# to the chart in "my_chart2"
my_chart2.add_indicator(indicator_name = 'sma',
series = my_series)
Method Signature
- .add_indicator(indicator_name, series, indicator_kwargs=None)
Creates a
IndicatorSeriesBase(descendant) that calculates theindicator_nametechnical indicator for the series provided inseries, and adds it to the chart’s.options.series.- Parameters:
indicator_name (
str) – The name of the indicator that should be added to the series and chart. For the list of supported indicators, please review the Indicator List.series (
strorSeriesBase) – The series to which the indicator should be added. Accepts either a series’.idas astr, or aSeriesBase(descendant) instance.indicator_kwargs (
dictorNone) – Keyword arguments to apply when instantiating the new indicator series. Defaults toNone.
- Returns:
Nothing. It simply changes the composition of the chart instance’s series to now include a new series with the indicator.
Assembling Your Chart and Options
Using Keyword Arguments
Note
The keyword pattern outlined below is supported by both the
ChartandHighchartsOptionsclasses
from highcharts_stock.chart import Chart
from highcharts_stock.options.series.area import LineSeries
# EXAMPLE 1. Indicating data and series_type.
my_chart = Chart(data = [[0, 1], [1, 2], [2, 3]],
series_type = 'line')
# EXAMPLE 2. Supplying the Series instance(s) directly.
my_chart = Chart(series = LineSeries(data = [
[0, 1],
[1, 2],
[2, 3]
]))
Note
.add_series()is supported by both theChartandHighchartsStockOptionsclasses
my_chart = Chart()
my_chart.add_series(my_series1, my_series2)
my_series = LineSeries()
my_chart.add_series(my_series)
Method Signature
- .add_series(self, *series)
Adds
seriesto theChart.options.seriesproperty.- Parameters:
series (
SeriesBaseor coercable) – One or more series instances (descended fromSeriesBase) or an instance (e.g.dict,str, etc.) coercable to one
Note
.from_series()is supported by both theChartandHighchartsStockOptionsclasses
my_series1 = LineSeries()
my_series2 = BarSeries()
my_chart = Chart.from_series(my_series1, my_series2, options = None)
Method Signature
- .from_series(cls, *series, kwargs=None)
Creates a new
Chartinstance populated withseries.- Parameters:
series (
SeriesBaseor coercable) – One or more series instances (descended fromSeriesBase) or an instance (e.g.dict,str, etc.) coercable to onekwargs (
dict) –Other properties to use as keyword arguments for the instance to be created.
Warning
If
kwargssets theoptions.seriesproperty, that setting will be overridden by the contents ofseries.
- Returns:
A new
Chartinstance- Return type:
from highcharts_stock.chart import Chart
from highcharts_stock.options.series.area import LineSeries
from highcharts_stock.options.series.bar import BarSeries
# Create a Chart instance called "my_chart" with an empty set of options
my_chart = Chart(options = {})
# Create a couple Series instances
my_series1 = LineSeries()
my_series2 = BarSeries()
# Populate the options series list with the series you created.
my_chart.options.series = [my_series1, my_series2]
# Make a new one, and append it.
my_series3 = LineSeries()
my_chart.options.series.append(my_series3)
Rendering Your Visualizations
from highcharts_stock.chart import Chart
from highcharts_stock.options.series.area import LineSeries
my_chart = Chart(data = [0, 5, 3, 5], series_type = 'line')
as_js_literal = my_chart.to_js_literal()
# This will produce a string equivalent to:
#
# document.addEventListener('DOMContentLoaded', function() {
# const myChart = Highcharts.chart('target_div', {
# series: {
# type: 'line',
# data: [0, 5, 3, 5]
# }
# });
# });
from highcharts_stock.chart import Chart
from highcharts_stock.global_options.shared_options import SharedOptions
my_chart = Chart(data = [0, 5, 3, 5], series_type = 'line')
# Now this will render the contents of "my_chart" in your Jupyter Notebook
my_chart.display()
# You can also supply shared options to display to make sure that they are applied:
my_shared_options = SharedOptions()
# Now this will render the contents of "my_chart" in your Jupyter Notebook, but applying
# your shared options
my_chart.display(global_options = my_shared_options)
Method Signature
- display(self, global_options=None, container=None, retries=5, interval=1000)
Display the chart in Jupyter Labs or Jupyter Notebooks.
- Parameters:
global_options (
SharedOptionsorNone) – The shared options to use when rendering the chart. Defaults toNoneThe ID to apply to the HTML container when rendered in Jupyter Labs. Defaults to
None, which applies the.containerproperty if set, and'highcharts_target_div'if not set.Note
Highcharts for Python will append a 6-character random string to the value of
containerto ensure uniqueness of the chart’s container when rendering in a Jupyter Notebook/Labs context. TheChartinstance will retain the mapping between container and the random string so long as the instance exists, thus allowing you to easily update the rendered chart by calling the.display()method again.If you wish to create a new chart from the instance that does not update the existing chart, then you can do so by specifying a new
containervalue.retries (
int) – The number of times to retry rendering the chart. Used to avoid race conditions with the Highcharts script. Defaults to 5.interval (
int) – The number of milliseconds to wait between retrying rendering the chart. Defaults to 1000 (1 second).
- Raises:
HighchartsDependencyError – if ipython is not available in the runtime environment
Downloading a Rendered Highcharts Visualization
from highcharts_stock.chart import Chart
my_chart = Chart(data = [0, 5, 3, 5],
series_type = 'line')
# Download a PNG version of the chart in memory within your Python code.
my_png_image = my_chart.download_chart(format = 'png')
# Download a PNG version of the chart and save it the file "/images/my-chart-file.png"
my_png_image = my_chart.download_chart(
format = 'png',
filename = '/images/my-chart-file.png'
)
Method Signature
- .download_chart(self, filename=None, format='png', server_instance=None, scale=1, width=None, auth_user=None, auth_password=None, timeout=0.5, global_options=None, **kwargs)
Export a downloaded form of the chart using a Highcharts Export Server.
- Parameters:
filename (Path-like or
None) – The name of the file where the exported chart should (optionally) be persisted. Defaults toNone.server_instance (
ExportServerorNone) – Provide an already-configuredExportServerinstance to use to programmatically produce the exported chart. Defaults toNone, which causes Highcharts for Python to instantiate a newExportServerinstance with all applicable defaults.format (
str) –The format in which the exported chart should be returned. Defaults to
'png'.Accepts:
'png''jpeg''pdf''svg'
scale (numeric) –
The scale factor by which the exported chart image should be scaled. Defaults to
1.Tip
Use this setting to improve resolution when exporting PNG or JPEG images. For example, setting
scale = 2on a chart whose width is 600px will produce an image file with a width of 1200px.Warning
If
widthis explicitly set, this setting will be overridden.width (numeric or
None) –The width that the exported chart should have. Defaults to
None.Warning
If explicitly set, this setting will override
scale.auth_user (
strorNone) – The username to use to authenticate against the Export Server, using basic authentication. Defaults toNone.auth_password (
strorNone) – The password to use to authenticate against the Export Server (using basic authentication). Defaults toNone.timeout (numeric or
None) – The number of seconds to wait before issuing a timeout error. The timeout check is passed if bytes have been received on the socket in less than thetimeoutvalue. Defaults to0.5.global_options (
HighchartsStockOptions,HighchartsOptionsorNone) – The global options which will be passed to the (JavaScript)Highcharts.setOptions()method, and which will be applied to the exported chart. Defaults toNone.
Note
All other keyword arguments are as per the
ExportServerconstructor.
from highcharts_stock.chart import Chart
from highcharts_stock.headless_export import ExportServer
custom_server = ExportServer(url = 'https://www.mydomain.dev/some_pathname_goes_here')
my_chart = Chart(data = [0, 5, 3, 5],
series_type = 'line')
# Download a PNG version of the chart in memory within your Python code.
my_png_image = my_chart.download_chart(format = 'png',
server_instance = custom_server)
# Download a PNG version of the chart and save it the file "/images/my-chart-file.png"
my_png_image = my_chart.download_chart(
format = 'png',
filename = '/images/my-chart-file.png',
server_instance = custom_server
)
Tip
Best practice!
If you are using a custom export server, it is strongly recommended that you
supply its configuration (e.g. the URL) via environment variables. For more information,
please see
headless_export.ExportServer.
Method Signature
- .download_chart(self, filename=None, format='png', server_instance=None, scale=1, width=None, auth_user=None, auth_password=None, timeout=0.5, global_options=None, **kwargs)
Export a downloaded form of the chart using a Highcharts Export Server.
- Parameters:
filename (Path-like or
None) – The name of the file where the exported chart should (optionally) be persisted. Defaults toNone.server_instance (
ExportServerorNone) – Provide an already-configuredExportServerinstance to use to programmatically produce the exported chart. Defaults toNone, which causes Highcharts for Python to instantiate a newExportServerinstance with all applicable defaults.format (
str) –The format in which the exported chart should be returned. Defaults to
'png'.Accepts:
'png''jpeg''pdf''svg'
scale (numeric) –
The scale factor by which the exported chart image should be scaled. Defaults to
1.Tip
Use this setting to improve resolution when exporting PNG or JPEG images. For example, setting
scale = 2on a chart whose width is 600px will produce an image file with a width of 1200px.Warning
If
widthis explicitly set, this setting will be overridden.width (numeric or
None) –The width that the exported chart should have. Defaults to
None.Warning
If explicitly set, this setting will override
scale.auth_user (
strorNone) – The username to use to authenticate against the Export Server, using basic authentication. Defaults toNone.auth_password (
strorNone) – The password to use to authenticate against the Export Server (using basic authentication). Defaults toNone.timeout (numeric or
None) – The number of seconds to wait before issuing a timeout error. The timeout check is passed if bytes have been received on the socket in less than thetimeoutvalue. Defaults to0.5.global_options (
HighchartsStockOptions,HighchartsOptionsorNone) – The global options which will be passed to the (JavaScript)Highcharts.setOptions()method, and which will be applied to the exported chart. Defaults toNone.
Note
All other keyword arguments are as per the
ExportServerconstructor.
Using Highcharts Stock Features
Stock tools are a custom toolbar that can be displayed on your chart which allows your users to interact with your chart in various ways. Using event bindings tied to the stock tools, you can toggle annotations, toggle technical indicators, or control the chart’s zoom level.
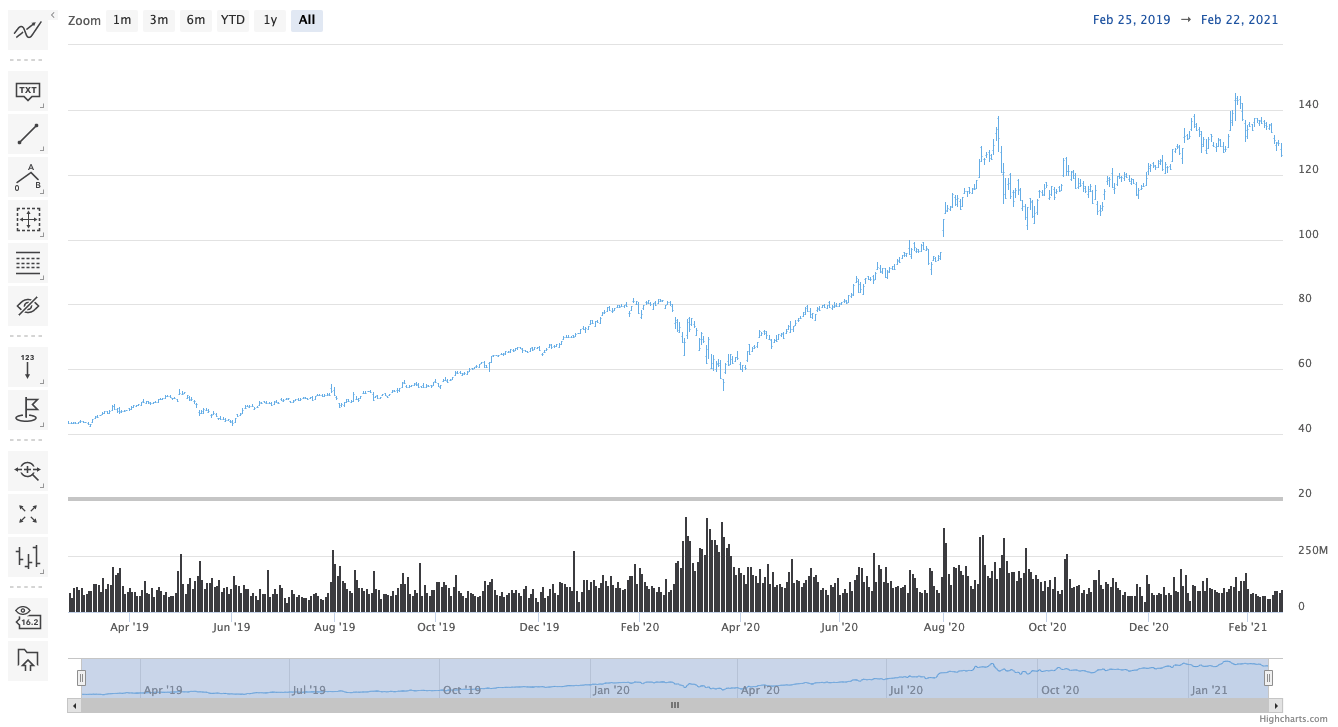
To display the stock tools in your chart, you can use the
HighchartsStockOptions.stock_tools
setting, which can be configured using a
StockTools instance.
my_stock_tools = StockTools(gui = { 'enabled': True }) my_options = HighchartsStockOptions(stock_tools = my_stock_tools) my_chart = Chart.from_options(my_options)See also
The Navigator is a small series shown below the main series which displays a zoomed-out view of the entire dataset. It allows you to zoom in / out or jump to a particular range of time in the chart.
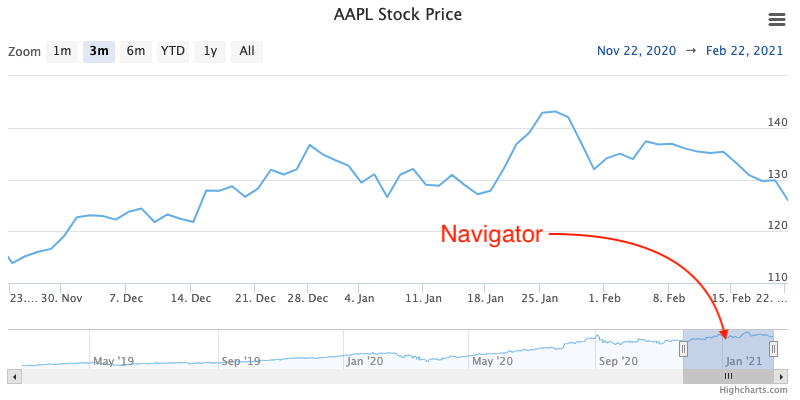
The navigator is enabled by default in Chart
instances where .is_stock_chart
is True or whose .options contain
a HighchartsStockOptions
instance.
You can configure how the navigator is rendered using several different methods:
You can configure whether individual series are shown in the navigator by setting their
.show_in_navigatorproperty toTrue(to show) orFalse(to hide)You can configure how the series is rendered within the navigator by setting their
.navigator_optionsproperty.You can set general navigator options for the series type by setting their
PlotOptions.<SERIES TYPE>.show_in_navigatorandPlotOptions.<SERIES TYPE>.navigator_optionsproperties.You can set overall configuration settings for the entire navigator using the
HighchartsStockOptions.navigatorsetting.
See also
The Range Selector is a small tool displayed above (or beside) the visualization which allows the user to pre-select the time range that is displayed on the chart.
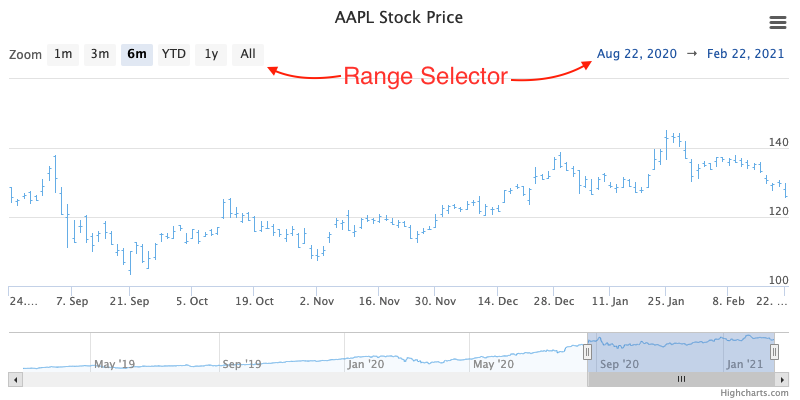
Based upon its configuration (via the
HighchartsStockOptions.options.range_selector
property), it can display a series of buttons that allow the user to zoom to a
specific granularity (e.g. display one day’s worth of data, display one week’s worth
of data, display one month’s worth of data, etc.) and can provide the user with inputs
to select the range (start date / end date) which should be displayed.
Note
By default, the range selector is rendered in a responsive fashion. If there is not
enough room to display the entire selector in a single row, it will collapse into a
dropdown configuration based on the
RangeSelector.dropdown
setting.
See also
RangeSelector